
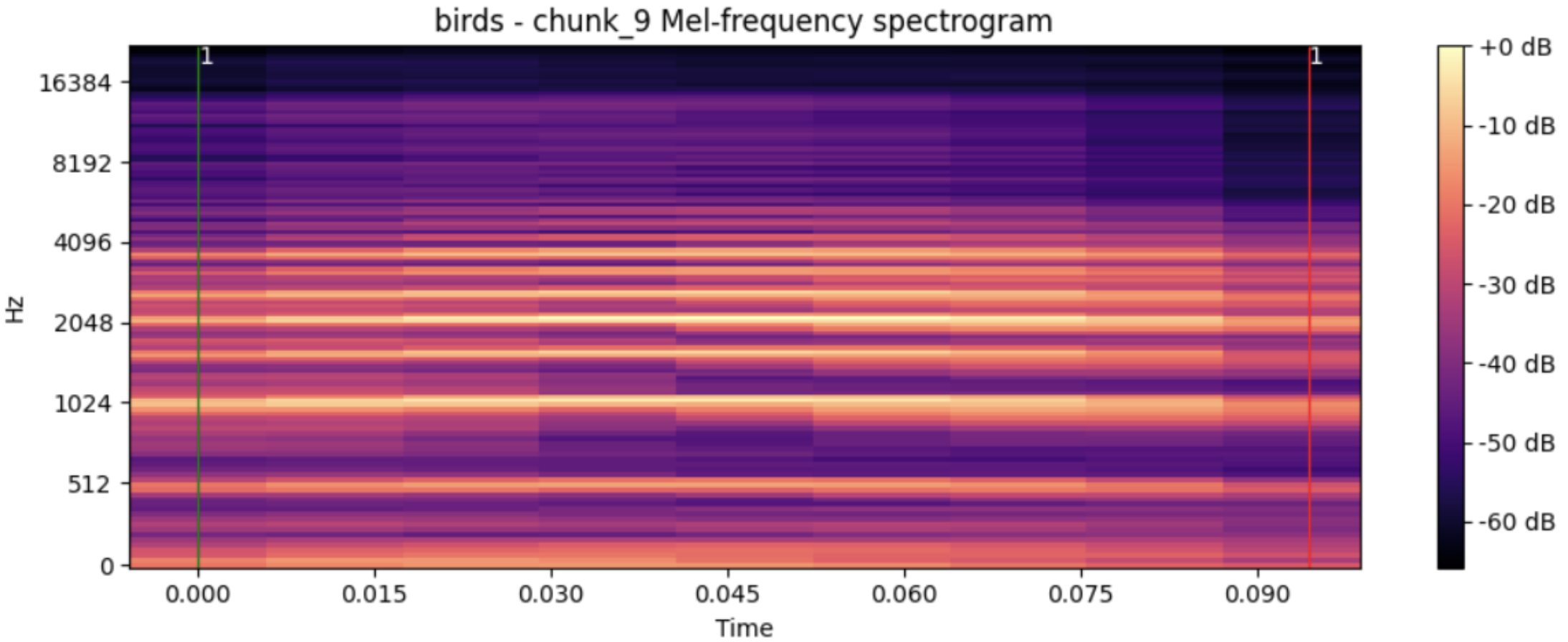
Short Audio Files
Individual files containing single vocalization events, ideal for training precise detection and classification models.
Bioacoustic monitoring is essential for ecological research and wildlife conservation, enabling the tracking of species and ecosystem health at scale without physical intervention. Yet, automated analysis of bioacoustic data remains challenging due to complex soundscapes with overlapping species, environmental variability, and high background noise.
We introduce a self-supervised learning framework tailored to large-scale bioacoustic recordings. Our method adapts the Masked Autoencoder paradigm to animal vocalizations and is trained on over 10,000 hours of terrestrial and marine recordings spanning 500 species. We demonstrate significant improvements over traditional methods in species identification, vocalization detection, and acoustic event classification.
Our contributions are threefold: (1) release of a 1B-parameter Vision Transformer encoder optimized for long bioacoustic sequences, (2) the largest bioacoustics dataset with standardized annotations, and (3) state of the art results on bioacoustic tasks including event detection and species classification.
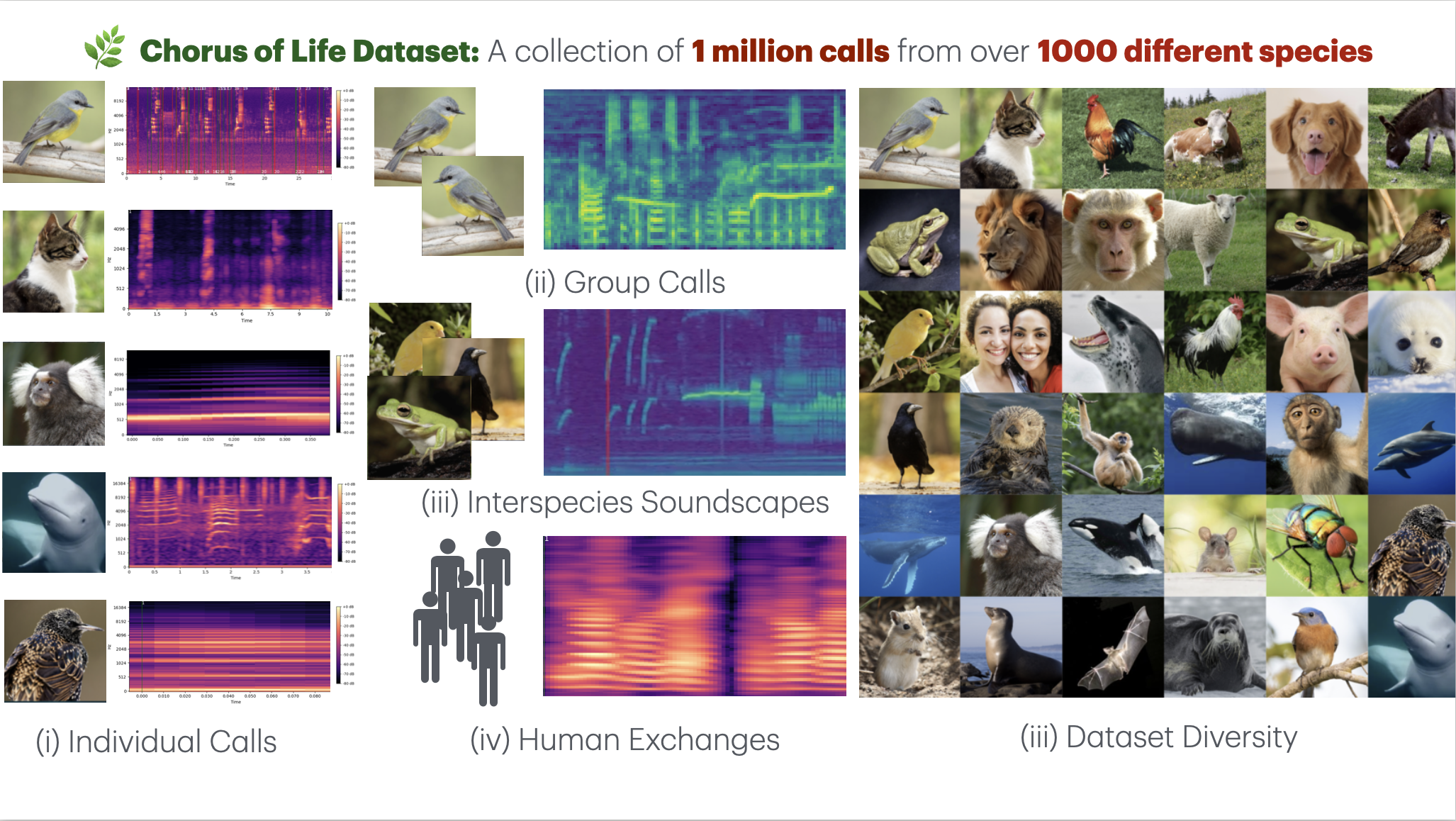
Figure: Overview of the unified bioacoustics dataset spanning diverse species and environments.
We have assembled the largest unified bioacoustics dataset to date, comprising over 1 million annotated vocalizations from more than 500 species across 30+ genera. Our dataset consolidates 30+ existing bioacoustics datasets under a unified annotation framework, enabling unprecedented scale and diversity in bioacoustic research.
Individual files containing single vocalization events, ideal for training precise detection and classification models.
Extended recordings with multiple overlapping calls and complex soundscapes, enabling training on realistic field conditions.
We concatenate two or more audio segments to form longer sequences, thereby increasing temporal diversity and exposing the model to transitions across different species and acoustic contexts. This augmentation encourages the encoder to capture long-range dependencies in the recordings.
We mix audio waveforms from different recordings by superimposing them, simulating overlapping vocalizations and complex natural soundscapes. This strategy trains the model to disentangle multiple sources and improves robustness to polyphonic bioacoustic environments.
We add synthetic or natural background noise to audio recordings, replicating common environmental disturbances such as wind, rain, or anthropogenic sounds. This augmentation improves the model's resilience to noisy conditions and enhances generalization to field recordings.
We randomly scale the amplitude of audio signals to mimic variability in microphone sensitivity, distance from the source, and propagation effects. This encourages the model to learn representations that are invariant to loudness and recording conditions.
These augmentation strategies enable our model to generalize across diverse acoustic environments and recording conditions, while the unified dataset provides unprecedented scale for training robust bioacoustic foundation models.
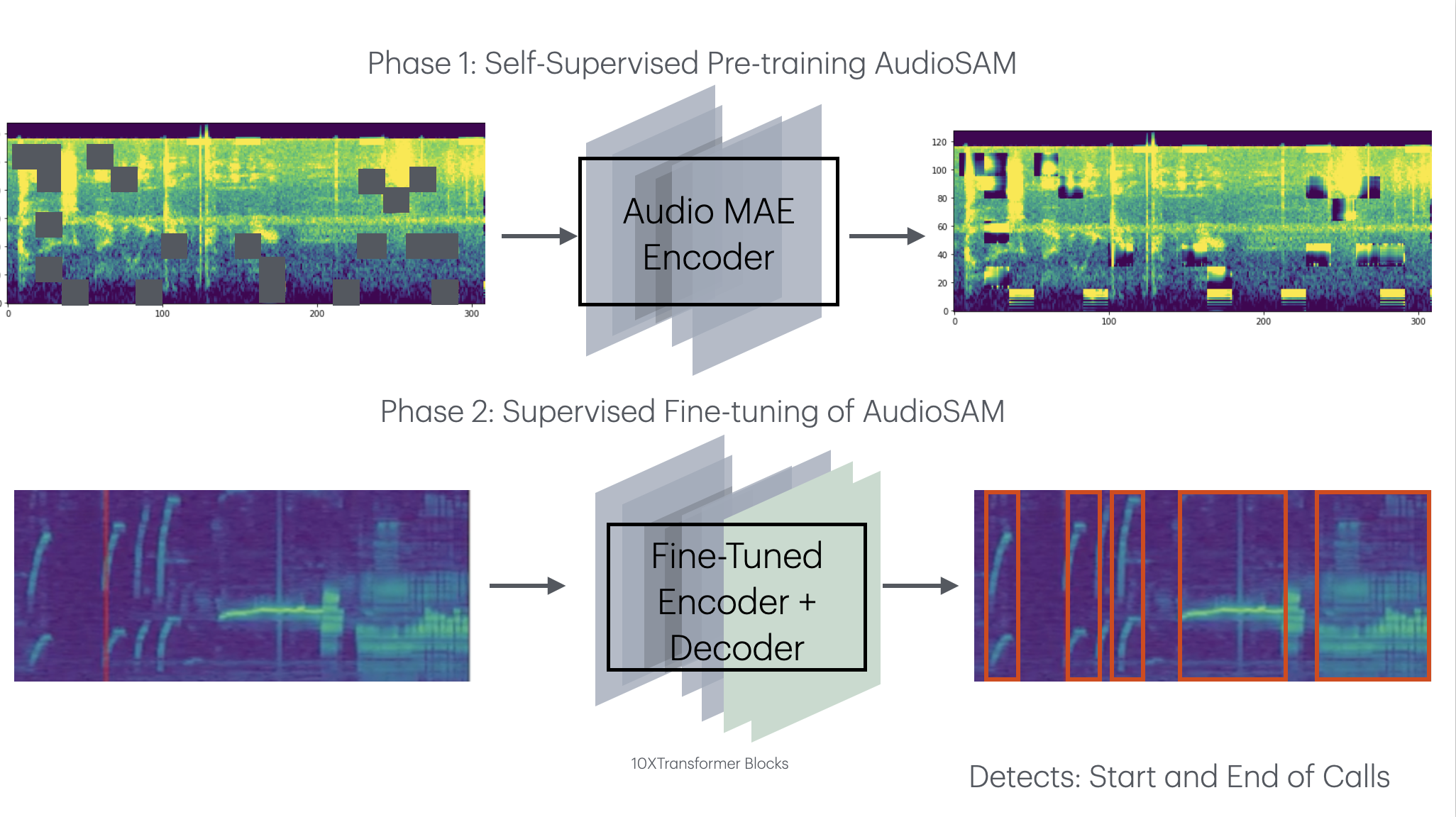
Figure: Architecture of the AudioSAM foundation model for bioacoustic analysis.
Our AudioSAM model is a 1B-parameter Vision Transformer encoder specifically designed for processing long bioacoustic sequences. The architecture leverages self-supervised learning through masked autoencoding to learn robust representations of animal vocalizations across diverse species and acoustic environments.
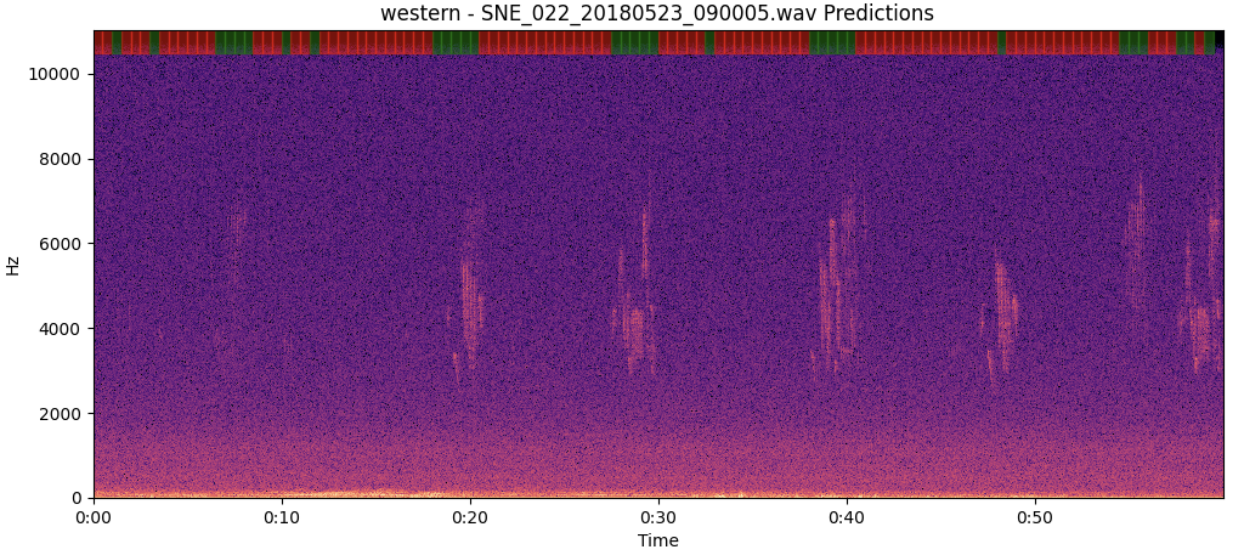
Start Frame
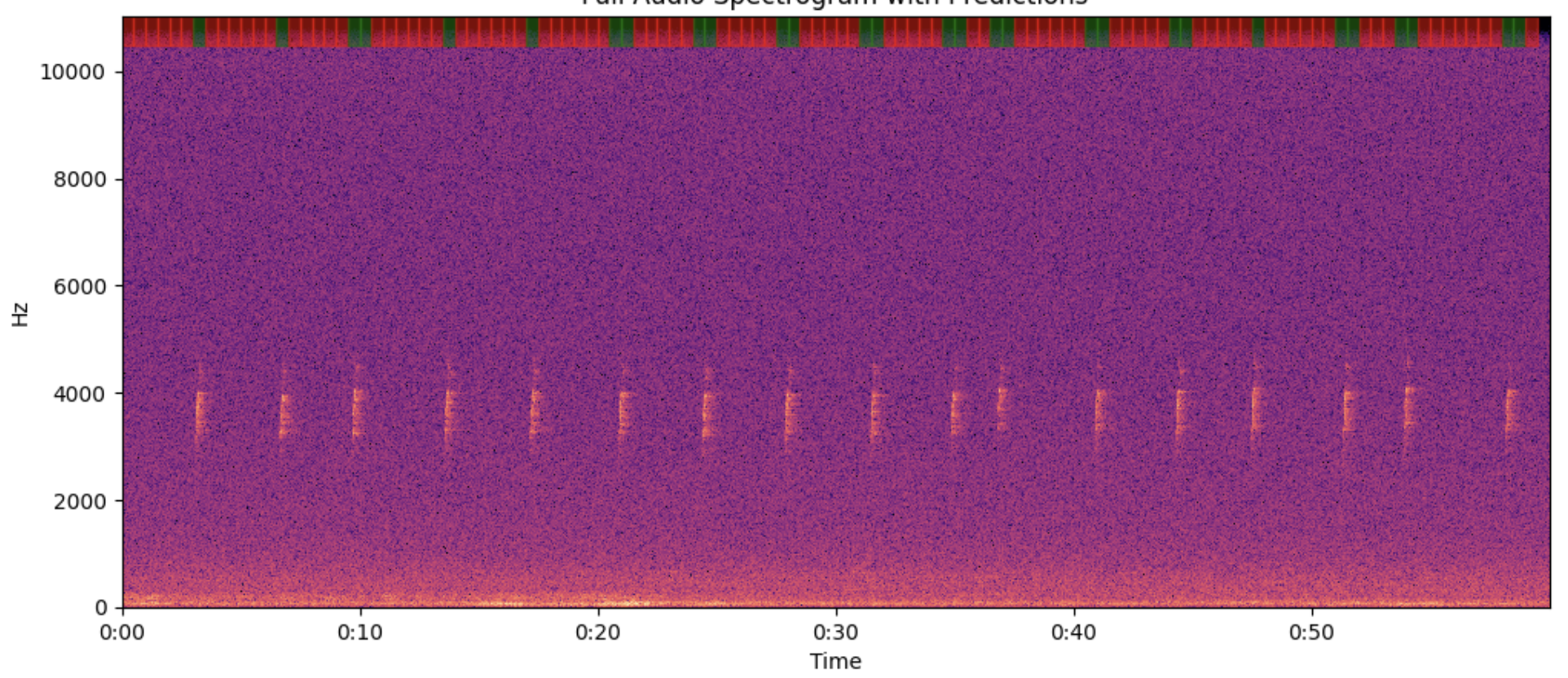
End Frame
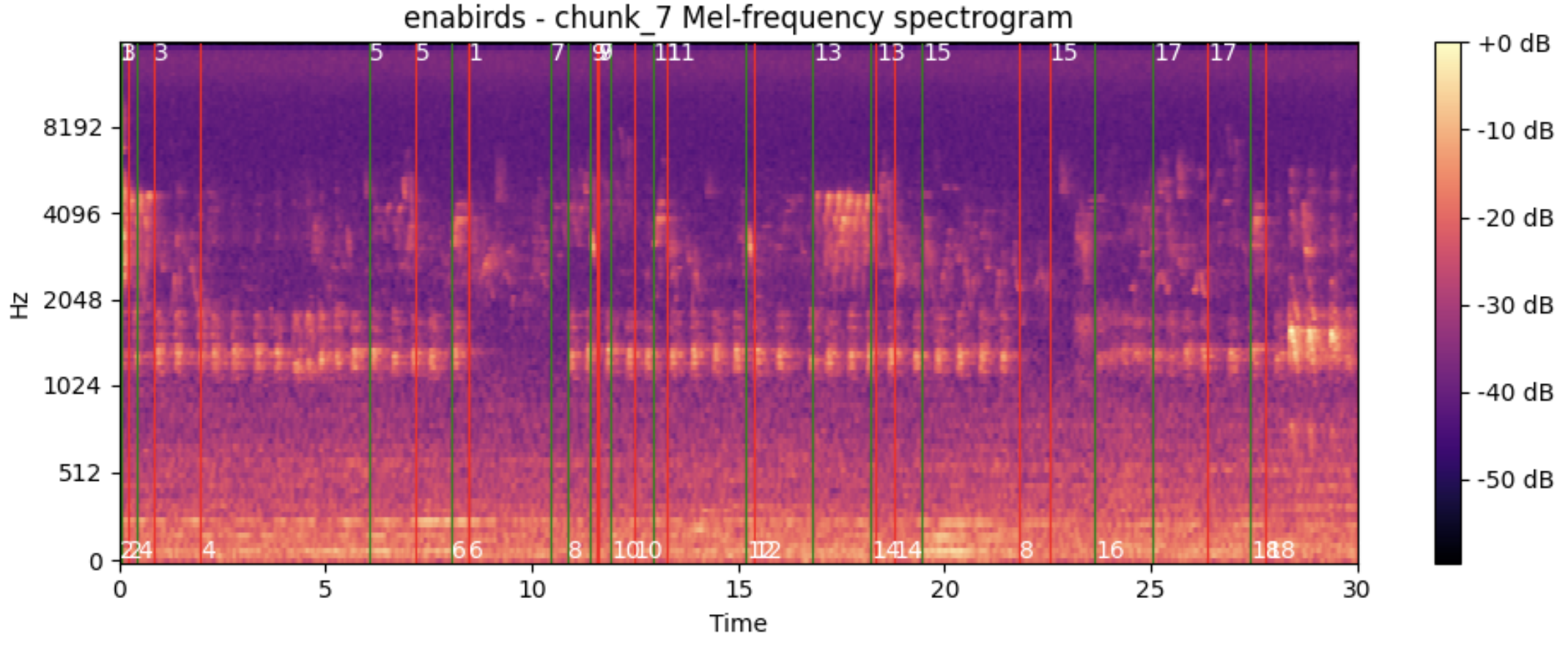
We evaluate our model's zero-shot performance on vocalization detection across multiple bioacoustic datasets, demonstrating superior generalization capabilities compared to existing methods.
| Model | DCASE | EnaBirds | Hiceas | Rainforest | Gibbons |
|---|---|---|---|---|---|
| LLM w/o audio | 0.000 | 0.001 | 0.210 | 0.000 | 0.013 |
| SALMONN | 0.005 | 0.004 | 0.097 | 0.002 | 0.005 |
| BioLingual | 0.036 | 0.109 | 0.429 | 0.004 | 0.018 |
| NatureLM-audio | 0.058 | 0.314 | 0.336 | 0.025 | 0.005 |
| Our Model | 0.282 | 0.902 | 0.304 | 0.111 | 0.041 |
Table 1. Zero-shot F1 scores on vocalization detection datasets. The best metric is highlighted for each dataset.